Retrieval-Augmented Generation (RAG) 가이드
개요
대용량 언어 모델(LLM)은 많은 언어 생성 작업에서 좋은 성능을 보여주고 있습니다. 그러나 이러한 모델은 특정 주제에 대한 정보를 생성하는 데 한계가 있습니다. 이러한 한계를 극복하기 위해 RAG는 검색을 통해 권위있는 정보를 가져와 생성하는 방식을 제안합니다. 이를 통해 모델은 특정 주제에 대한 정보를 검색하여 가져와 이를 기반으로 생성을 수행할 수 있습니다.
RAG를 사용한 텍스트 생성 작업은 다음과 같은 다이어그램으로 설명할 수 있습니다.
출처: AWS

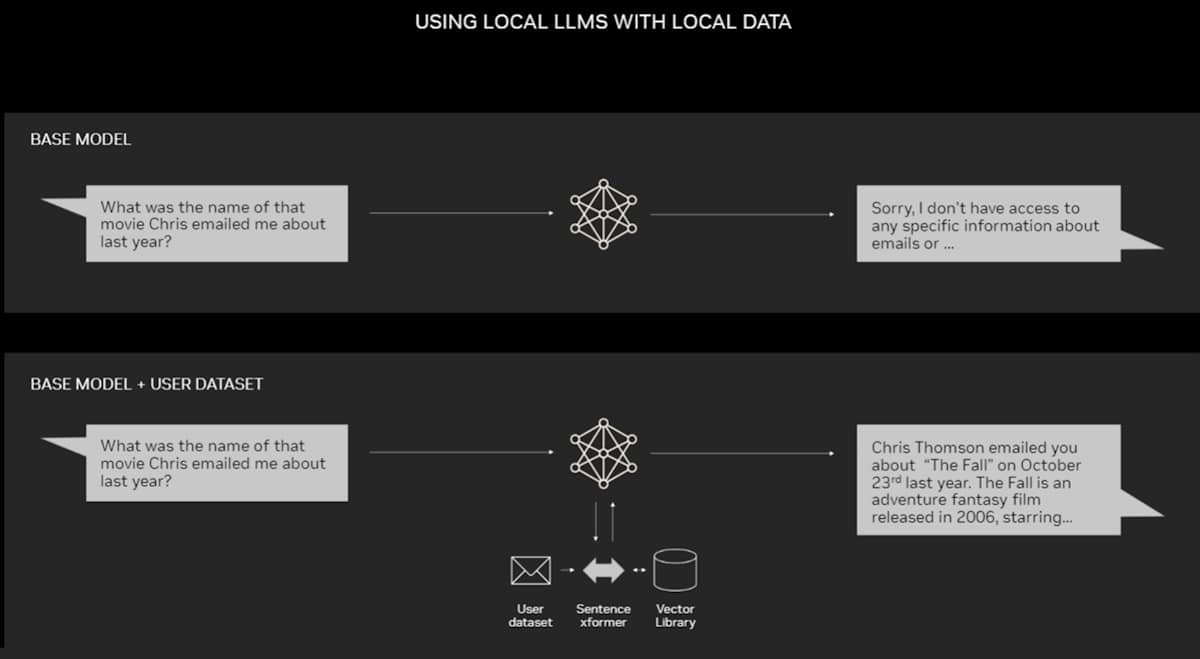
예를 들어, "작년에 크리스가 보낸 이메일의 영화가 무엇인가요?"라는 질문에 대한 답변을 생성하는 경우, RAG는 먼저 이메일에 대한 정보를 검색하여 가져온 후, LLM은 사전 지식 없이는 답변을 할 수 없습니다. RAG를 사용하면 이메일에 대한 정보를 가져와 이를 기반으로 답변을 생성할 수 있습니다.
출처: NVIDIA
Langchain 그리고 RAG
Langchain은 다양한 RAG 모델과 파이프라인을 구축하는데 편리한 API를 제공하는 라이브러리입니다. Langchain을 사용하면 다양한 RAG 모델을 쉽게 사용할 수 있습니다.
단계별로 정리
-
Indexing: 데이터 로딩 (load) 필요한 데이터를 로딩하는 단계로, 크게
file그리고web로더들을 지원합니다. -
Indexing: 데이터 정제 및 분리 (transform / split) 로딩한 문서들을 형식에 따라 정제하고 LLM 모델 사용에 적합하도록 분리하는 모듈입니다.
Langchain은 다음과 같은 Text Splitter들을 지원합니다:
-
Indexing: 데이터 저장 (store) 분리된 데이터를 저장하는 모듈입니다. 저장시 벡터스토어에 텍스트 임베딩 형식으로 저장합니다.
참조: 채널톡 블로그
다음과 같은 임배딩과 벡터 스토어를 지원합니다:
-
Retrieval: 데이터 불러오기 (RAG)
저장된 데이터에서 LLM이 사용할 수 있는 가장 적합한 도큐먼트를 불러옵니다.
Langchain에서는 다음과 같은 Retriever를 지원합니다. (Retriever 문서)
-
Generation: LLM을 사용한 최종 결과물 생성 불러온 데이터를 기반으로 LLM에게
context(배경 지식)을 제공하여 더 양질의 텍스트를 생성합니다.
Langchain 구현 예제
다음은 Langchain을 통해 RAG를 사용하여 LLM 모델을 호출하는 파이프라인 코드 예제입니다.
/**
* 1) 데이터 로딩
* Cheerio 웹 로더를 사용하여 주어진 URL의 문서를 로딩합니다.
*/
const loader = new CheerioWebBaseLoader(
// LLM 기반 자율 에이전트 문서입니다.
"https://lilianweng.github.io/posts/2023-06-23-agent/"
);
const docs = await loader.load();
/**
* 2) 데이터 정제
* 이 경우 문서를 1000자의 청크로 나누고 청크 사이에 200자의 중첩을 둡니다.
* 중첩은 문장과 관련된 중요한 문맥이 분리될 가능성을 줄이는 데 도움이 됩니다.
*/
const textSplitter = new RecursiveCharacterTextSplitter({ chunkSize: 1000, chunkOverlap: 200 });
const splits = await textSplitter.splitDocuments(docs);
/**
* 3) 데이터 저장
* 이 경우 MemoryVectorStore를 사용하여 메모리(RAM)에 불러온 데이터를 저장합니다.
* OpenAI 임베딩 형식으로 저장합니다.
*/
const vectorStore = await MemoryVectorStore.fromDocuments(splits, new OpenAIEmbeddings());
/**
* 4) 데이터 불러오기
* VectorStore Retriever를 사용하여 "What is task decomposition?"
* 이라는 질문에 가장 유사한 문서를 불러옵니다.
*/
const retriever = vectorStore.asRetriever();
const retrievedDocs = await retriever.getRelevantDocuments("what is task decomposition")
// 프롬프트 불러오기
const prompt = await pull<ChatPromptTemplate>("rlm/rag-prompt");
// LLM 모델 불러오기
const llm = new ChatOpenAI({ modelName: "gpt-3.5-turbo", temperature: 0 });
/**
* 5) RAG 체인 실행 및 결과물 생성
*/
const ragChain = await createStuffDocumentsChain({
llm,
prompt,
outputParser: new StringOutputParser(),
})
프롬프트 템플릿:
귀하는 질문 답변 작업의 보조자입니다. 검색된 다음 문맥을 사용하여 질문에 답하세요. 답을 모른다면 모른다고 말하세요. 답변은 최대 세 문장으로 간결하게 작성하세요.
질문: {question}
문맥: {context}
Answer:
-------------------------------------------------------------------------------------
You are an assistant for question-answering tasks. Use the following pieces of retrieved context to answer the question. If you don't know the answer, just say that you don't know. Use three sentences maximum and keep the answer concise.
Question: {question}
Context: {context}
Answer:
5번 단계에서 호출되는 프롬프트는 다음과 같습니다.
You are an assistant for question-answering tasks. Use the following pieces of retrieved context to answer the question. If you don't know the answer, just say that you don't know. Use three sentences maximum and keep the answer concise.
Question: What is task decomposition?
Context: Fig. 1. Overview of a LLM-powered autonomous agent system.
Component One: Planning#
A complicated task usually involves many steps. An agent needs to know what they are and plan ahead.
Task Decomposition#
Chain of thought (CoT; Wei et al. 2022) has become a standard prompting technique for enhancing model performance on complex tasks. The model is instructed to “think step by step” to utilize more test-time computation to decompose hard tasks into smaller and simpler steps. CoT transforms big tasks into multiple manageable tasks and shed lights into an interpretation of the model’s thinking process.
Tree of Thoughts (Yao et al. 2023) extends CoT by exploring multiple reasoning possibilities at each step. It first decomposes the problem into multiple thought steps and generates multiple thoughts per step, creating a tree structure. The search process can be BFS (breadth-first search) or DFS (depth-first search) with each state evaluated by a classifier (via a prompt) or majority vote.
Task decomposition can be done (1) by LLM with simple prompting like "Steps for XYZ.\n1.", "What are the subgoals for achieving XYZ?", (2) by using task-specific instructions; e.g. "Write a story outline." for writing a novel, or (3) with human inputs.
Another quite distinct approach, LLM+P (Liu et al. 2023), involves relying on an external classical planner to do long-horizon planning. This approach utilizes the Planning Domain Definition Language (PDDL) as an intermediate interface to describe the planning problem. In this process, LLM (1) translates the problem into “Problem PDDL”, then (2) requests a classical planner to generate a PDDL plan based on an existing “Domain PDDL”, and finally (3) translates the PDDL plan back into natural language. Essentially, the planning step is outsourced to an external tool, assuming the availability of domain-specific PDDL and a suitable planner which is common in certain robotic setups but not in many other domains.
Self-Reflection#
The AI assistant can parse user input to several tasks: [{"task": task, "id", task_id, "dep": dependency_task_ids, "args": {"text": text, "image": URL, "audio": URL, "video": URL}}]. The "dep" field denotes the id of the previous task which generates a new resource that the current task relies on. A special tag "-task_id" refers to the generated text image, audio and video in the dependency task with id as task_id. The task MUST be selected from the following options: {{ Available Task List }}. There is a logical relationship between tasks, please note their order. If the user input can't be parsed, you need to reply empty JSON. Here are several cases for your reference: {{ Demonstrations }}. The chat history is recorded as {{ Chat History }}. From this chat history, you can find the path of the user-mentioned resources for your task planning.
Agent System Overview
Component One: Planning
Task Decomposition
Self-Reflection
Component Two: Memory
Types of Memory
Maximum Inner Product Search (MIPS)
Component Three: Tool Use
Case Studies
Scientific Discovery Agent
Generative Agents Simulation
Proof-of-Concept Examples
Challenges
Citation
References
Answer:
해당 문서에서 예제 코드의 전체적인 실행계획을 볼 수 있습니다.
최종 답변:
Task decomposition is a technique used to break down complex tasks into smaller and simpler steps. It can be done through methods such as chain of thought (CoT) or tree of thoughts, where the task is transformed into multiple manageable tasks. Task decomposition can also be achieved through simple prompting, task-specific instructions, or with human inputs.